Introduction
In a clinical trial or clinical study, an investigational treatment is administered to subjects, and the resulting outcome data are collected and analyzed after a certain period of time. Most statistical analysis methods do not include the length of time as a variable, and analysis is made only on the trial outcomes upon completion of the study period, as specified in the study protocol. However, in cases where the outcome yields different interpretations at different points in time, even over a range of only several hours or minutes, it is advantageous to use a statistical analysis method incorporating time as a variable [1]. Poisson regression and survival analysis are typical statistical analysis approaches that analyze the variable which includes the information of the time [2].
The Korean Journal of Anesthesiology has thus far published several papers using survival analysis for clinical outcomes: a comparison of 90-day survival rate for pressure ulcer development or non-development after surgery under general anesthesia [3], a comparison of postoperative 5-year recurrence rate in patients with breast cancer depending on the type of anesthetic agent used [4], and a comparison of airway intubation success rate and intubation time between two types of video laryngoscopy in difficult intubation cases [5]. It is not hard to consider the application of survival analysis for the data of first two articles, using survival analysis for the intubation time comparison in the third paper is not easy to think. For such topics, the main obstacle to the widespread use of survival analysis is the word “survival,” which leads to the misunderstanding that can only be used for data related to death or failure. However, as is the case with the third paper, survival analysis can be applied not only to data of patients’ death, but also to any data related to an “event of interest” that may or may not occur during the observation period.1) The following are several examples of questions for which survival analysis may be applied:
1) How long does symptom improvement last after an epidural injection? (Time to the recurrence of back pain and recurrence vs. non-recurrence)
2) How long is the duration of the effect of antiemetic prophylaxis given to prevent nausea and vomiting resulting from the use of intravenous patient-controlled opioid analgesia? (Duration of nausea/vomiting prevention and manifestation vs. non-manifestation)
3) How long does it take for postoperative cognitive dysfunction caused by general anesthesia to occur? (Time to the occurrence of cognitive dysfunction and occurrence vs. non-occurrence)
In all three examples, after the treatment (epidural injection, administration of antiemetic prophylaxis, administration of general anesthesia), the subsequent event (recurrence of back pain, manifestation of nausea/vomiting, occurrence of cognitive dysfunction) may or may not occur during the specified observation period, and the patient status (occurrence or non-occurrence) and length of time (observation period) are assigned to each participant as variables.
In cases where only rates of occurrence are compared, without regard to the lapse of time until occurrence, the chi-squared test or Fisher’s exact test are sufficient. Conversely, in cases where the time-to-event of interest is analyzed, if the event of interest has occurred for all participants, Student’s t-test or the Mann-Whitney U test may be used. However, even in such cases, non-occurrence or termination of participation (due to improvement or exacerbation, moving, death, etc.) often cannot be ruled out. Also, the observation period may vary due to a limited study period or different outcome time frames. For these reasons, some of data are subject to incompleteness, and these data should be analyzed using another statistical method or excluded. Survival analysis is necessary to analyze incomplete data by setting the time-to-event as a primary outcome. In summary, survival analysis can be applied in a range of situations in which any event of interest (not just mortality) is analyzed in terms of its occurrence or non-occurrence during a specified observation period [1].
Like other statistical methods, survival analysis can be performed using parametric or non-parametric methods. In anesthesia and pain medicine, non-parametric survival analysis is usually preferred because in most cases the data do not satisfy the prerequisites of parametric survival analysis. In parametric survival analysis, a survival model is constructed by performing regression analysis on the assumption that the outcome variables follow a conventionally known distribution, such as the normal distribution, binomial distribution, or Poisson distribution. Common parametric survival models include the Weibull, exponential, log-logistic, lognormal, and generalized gamma models. Non-parametric survival analysis is most commonly performed using the Kaplan-Meier method or Cox proportional hazards regression modeling. In this paper, only non-parametric survival analysis is examined.
Censored Data
Ideal data for survival analysis are those yielded by cases in which the time of treatment is clearly established and all participants are followed up until they experience the event. However, the observation period may end without occurrence of the event because it may be difficult in practice to study all the participants until the occurrence of the event, and because participants can drop out during the observation period. Post-treatment data unavailable for confirmation of occurrence or non-occurrence during the follow-up period are termed censored data2) and are excluded from analysis as missing values in other statistical analysis methods; in survival analysis, however, they are processed as important data influencing the outcome [6,7].
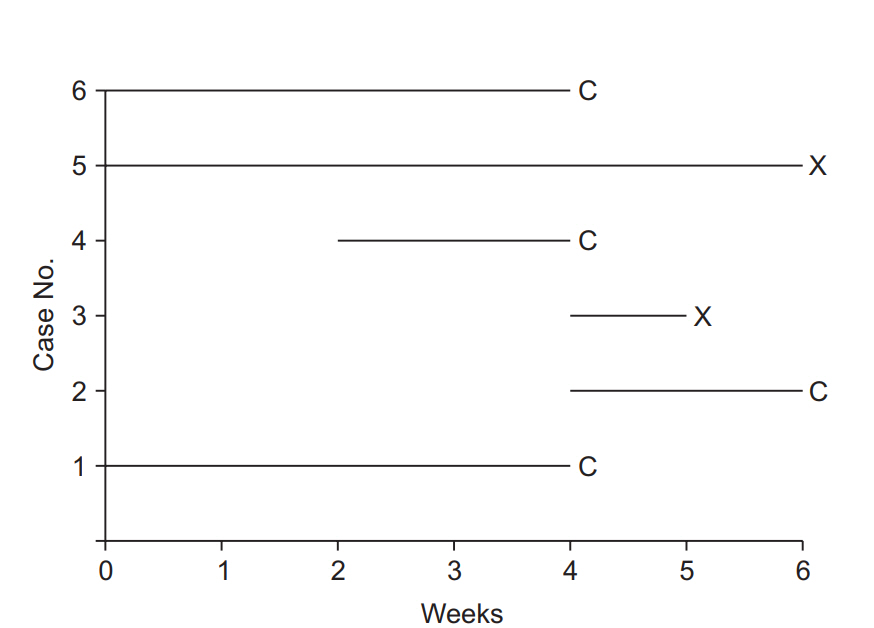
For example, suppose that a clinical study is conducted to examine the efficacy of a new drug for back pain, in which the treatment and event are epidural injection of the new drug and recurrence of back pain, respectively. If it is impossible to confirm recurrence for various reasons such as a car accident, death caused by other diseases, or unavailability of the data needed to confirm recurrence due to movement to another hospital, such cases should be processed as censored data. In censored data, recurrences prior to the last follow-up can be confirmed, but any recurrence after the termination of follow-up cannot be confirmed. Fig. 1 illustrates details of an imaginary study in which six patients were followed over a period of six weeks. Patient 1 participated in the study from the beginning and developed recurrence of back pain in week 4 in the aftermath of a car accident, and therefore is processed as censored data. This data point provides the effectiveness of new drug for 4-week observation. Patient 2 was enrolled in the study in the fourth week, and no recurrence was observed up to week 6. This case of non-recurrence until the end of the observation period is also processed as censored data, with the 2-week follow-up included in the analysis. Patient 3 was enrolled in the fourth week and developed recurrence in week 5; this is a case of a complete data point, with the 1-week follow-up and recurrence included in the analysis. Patient 4 was enrolled in the second week, but the observation was pre-terminated due to loss to follow-up from week 4 onward, resulting in a two-week observation period. Patient 5 participated in the study from the beginning and developed recurrence in week 6, and therefore yields a complete data point. Patient 6 is a case of censored data due to withdrawal caused by uncovered random allocation in week 4, with the 4-week follow-up included in the analysis. To conclude, data related to the occurrence of the treatment-related event are complete data, coded as “X,” and data without indication of occurrence or with occurrence for reasons other than the treatment are censored data, coded as “C” [8].
Survival Function, Hazard Function
“Survival function” is a key term in survival analysis, along with “censoring” and “event.” The concept of a survival function is essential for the understanding of survival analysis.
The survival function is defined as the probability of the outcome event not occurring up to a specific point in time, including the time point of observation (t), and is denoted by S(t). That is, if the event is “recurrence of back pain,” it is the “probability of not having back pain” up to a specific time. In the survival function (Equation 1),3) t = 0 corresponds to a probability of 1.0 (i.e., 100% survival at the onset), and the point in time with 50% survival probability is the median survival time.
The ratio of the number of events occurring during the entire study period to the total number of observations is termed the “incidence rate.” For example, if the event is death, mortality is the incidence rate. However, since the incidence may not be constant throughout the study period, it may be necessary to calculate the incidence rate at a specific time (t). First, the incidence rate for the period between a specific time t and the next measurement time t + α can be calculated by dividing the number of events occurring between t and t + α by the total number of observations at time t. By α approaches 0, i.e., by taking the limit as the interval between t and t + α closes to 0, the instantaneous incidence rate at t, which constitutes the hazard, can be calculated.4) The hazard function is a function for calculating the instantaneous incidence rate at any given point in time, and is denoted by h (t) [9].
Survival Analysis Using Kaplan-Meier Curves (Estimates)
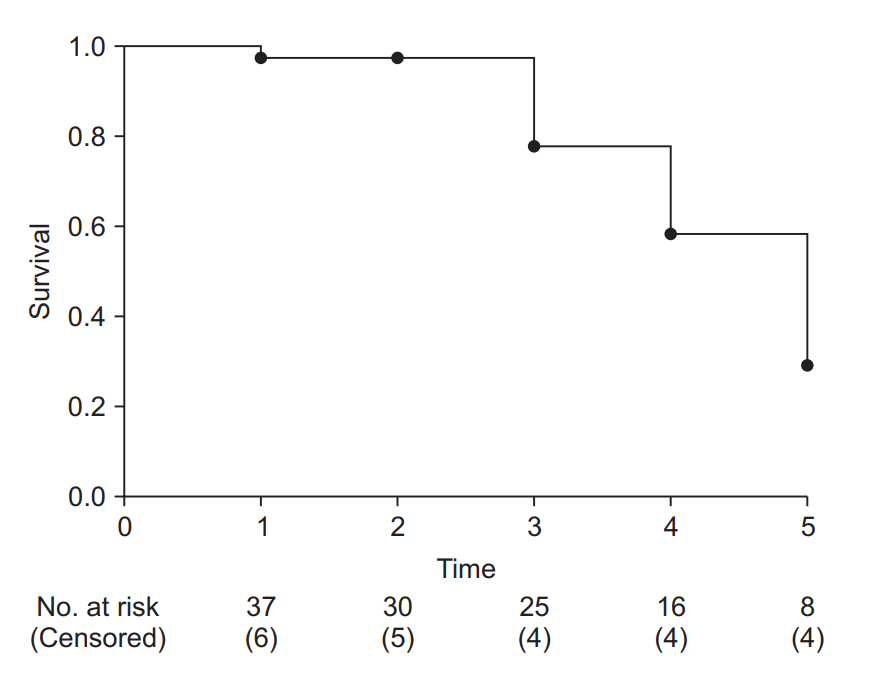
In the Kaplan-Meier method, the incidence rate as a function of time is calculated by putting the observations in ascending order of time until occurrence. Analysis of the example data in Fig. 1 with the Kaplan-Meier method should thus start by setting the baseline observation of each participant as time 0 (Fig. 2). After arranging all data points, the incidence rate is calculated at each occurrence of the event, followed by survival curve estimation. With the focus of the Kaplan-Meier method on only two variables, namely the observation period and the occurrence/non-occurrence of the event, other variables possibly influencing the occurrence of the event, such as sex and age in the case of the recurrence of back pain, are excluded from analysis [10].
Fig. 3 illustrates the interpretation of the Kaplan-Meier survival curve. Although no standard has yet been established, it is a general practice to show censored data as points or symbols, and decreases in the survival rate (corresponding to the occurrences of the event) as steps. As time points close to the end of study period, the number of participants tend to be decrease abruptly, an incidence rate calculated in this period could not provide clinical significance. So, it is recommended to indicate the number of patients at each calculation point. Some journals set out standards for survival curve creation [11].
Kaplan-Meier survival analysis is used to test for significant differences between survival curves and in median or mean survival time. Therefore, it lends itself well to studies focusing on survival time, i.e., time to the occurrence of the event of interest.
Multiple comparison method for Kaplan-Meier survival analysis
Among the methods for comparing two or more Kaplan-Meier survival curves, such as the Mantel-Haenszel method, log-rank method (Mantel-Cox), Gehan’s generalized Wilcoxon method (Breslow test), and likelihood ratio, the logrank method is most widely used.5) The null hypothesis tested with the log-rank method is that “there is no overall difference between the two survival curves to be compared.” The observed count and the expected count are compared using the chi-square test. The log-rank method is known to have good statistical power when there are considerable differences in the incidence rate among the groups being compared. If three or more groups are compared, pairwise multiple comparisons can also be performed using post-hoc tests such as the Bonferroni test and Holm-Sidak method [12].
Just as the independent t-test should be preceded by testing for normality, the log-rank method is based on several assumptions. The first is the proportional hazards assumption, according to which the hazard ratio (defined in equation 2) should be constant throughout the study period.6) For example, the incidence rate of postoperative nausea/vomiting is highest immediately after surgery and decreases with time, regardless of whether the type of general anesthesia is inhalational or intravenous. That is, the risk of postoperative nausea/vomiting varies (decreases) with time independently of the type of anesthesia. If the proportional hazards assumption is valid, then a finding that the risk of postoperative nausea/vomiting in the patient group receiving an inhalational anesthetic agent is twice that of the patient group receiving an intravenous anesthetic means that there is a twofold difference in hazard at all points in time. With the hazard ratio greater than 1, there is a greater risk of postoperative nausea/vomiting in the inhalational anesthesia group than in the intravenous anesthesia group.7) As illustrated by this example, the hazard ratio offers information that may allow understanding hazard information at a glance [13] (Equation 2).
The proportional hazards assumption and hazard ratio are also important for the Cox proportional regression model, to be explained below [14]. If the proportional hazards assumption is not valid, Gehan’s generalized Wilcoxon test (Breslow test), in which the number of patients exposed to the hazard at the observation point is applied as a weighting factor (instead of 1), or other methods should be used [15].
An example of Kaplan-Meier survival analysis
The results of the survival analysis presented below are derived from imaginary study data on the manifestation/non-manifestation of nausea/vomiting during the first 24 postoperative hours in two groups that received two different antiemetics (Table 1). For convenience of analysis, only age, body weight, and the choice of two of opioid analgesics used intraoperatively are used for analysis. To facilitate understanding, several analytic methods are presented to the same data.
Table 2 outlines the demographic characteristics of the patients included in the study. Although there are not many withdrawals before symptom manifestation in a 24-hour postoperative observational study in actual clinical settings, this virtual study includes a substantial number of dropout patients. Of 104 patients in total, 51 patients (Group A) received antiemetic agent A and 53 patients (Group B) received antiemetic agent B. In Groups A and B, the counts of nausea/vomiting symptoms manifested by the end of 24 postoperative hours are 25 (49.0%) and 38 (71.7%), respectively, and intergroup difference are verified to be statistically significant by the chi-square test (χ2(1) = 5.597, P = 0.018, Cohen’s Φ [phi] = 0.23). The relative risk for Group A compared to Group B is 0.7 (95% CI: 0.5–0.9). Similar results are yielded by incidence rate estimation, although it is an overlapping method, in which the nausea/vomiting symptoms manifested during the first 24 postoperative hours account for 49.0% (95% CI: 35.3–62.7%) of patients in Group A and 71.7% (95% CI: 59.6–83.8%) in Group B, showing a significant intergroup difference (z-test, P = 0.018, Cohen’s h = 0.47). These statistics reflect the results including all censored data without manifestation of nausea/vomiting during the first 24 hours. Given that nausea/vomiting symptoms are potentially observable among the patients with censored data during the study period (24 hours), the accuracy of the above results may not be high. Excluding all censored cases without nausea/vomiting before the first 24 postoperative hours, the number of patients included in the analysis is 73, and the incidence rate recalculated accordingly is 89.3% (95% CI: 77.8–100.0%) for Group A and 84.4% (95% CI: 73.9–95.0%) for Group B. These increased incidence rates reflect the omission of patients who dropped out of the study before completing it (24-hour observation) without manifesting symptoms of nausea/vomiting. Regardless of the researcher’s intention, the actual incidence rates are overestimated due to the omission of patients without symptom manifestation.
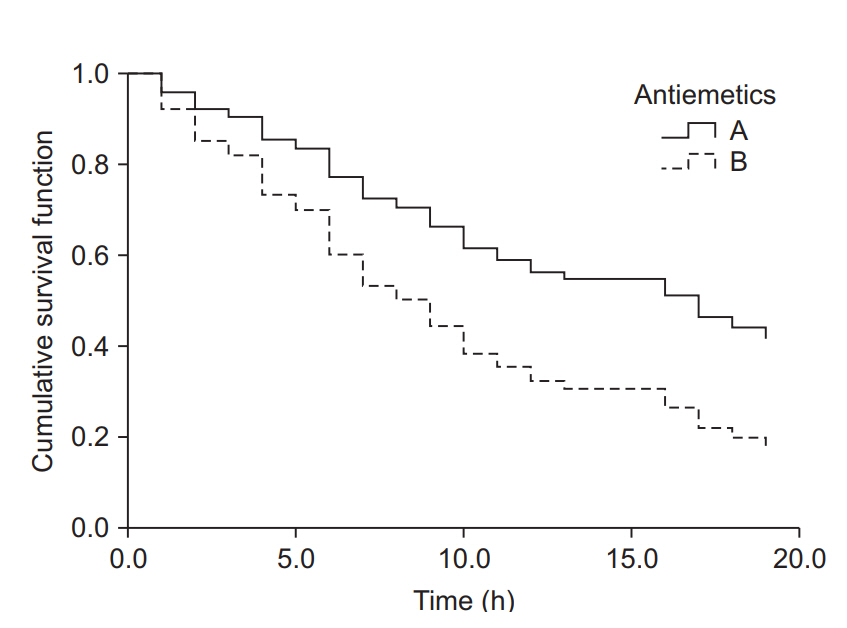
The results of Kaplan-Meier survival analysis for the same datasets are as follows (the observed counts of the event and other results overlapping with those presented above are omitted). The median survival time (length of time free of the target event) is 13.0 hours (25-75%: 8.0–24.0 hours) for Group A and 6.0 hours (25-75%: 3.0-17.0 hours) for Group B; the intergroup difference assessed by the log-rank method is statistically significant (χ2(1) = 6.802, P = 0.009). Examination of the Kaplan-Meier curves for the two groups shows that the cumulative survival rate of Group B rapidly decreases with time compared with that of Group A (Fig. 4).
Cox Proportional Hazards Regression Model
In the Cox proportional hazards regression model, regression analysis is used to process censored data. This method does not presuppose any specific distribution and can analyze any variables that may influence the occurrence, unlike Kaplan-Meier survival analysis, and is thus regarded as a semiparametric method [16,17].
The Cox proportional hazards regression model is based on two assumptions: first, the survival function is an exponential function; second, the hazard ratio for the two compared groups is constant throughout the study period. In other words, the hazard ratio is a constant (HR = λ), and the survival function at any given point in time is expressed as an exponential function of the hazard ratio (s(t) = exp−λt). The null hypothesis for comparison of two survival curves is that “the hazard ratio for the two groups is 1.”
In the Cox proportional hazards regression model, result is derived from the comparison between the risk levels of the occurrence and non-occurrence influenced by a variable which could affect the outcome [18]. The result is an estimate of the hazard ratio of that variable, and is calculated as the corresponding regression coefficient in the regression model. If the hazard ratio of a variable is greater than 1 and poses statistically significance, that variable contributes to increasing the probability of occurrence of the event.
If the hazard ratio of two groups are not maintained at a constant level, a different analysis method should be considered. The Cox proportional hazards regression model cannot be used for analysis in such cases, because a hazard ratio changing with time implies that there may be more than one estimate for the regression coefficient over time. Along with the assumption related to the hazard ratio, basic assumptions required for any sort of regression analysis, such as continuity of variables and absence of interactions between variables, should of course be taken into account [19,20].8)
An example of regression analysis with the Cox proportional hazards regression model
Using the Cox proportional hazards regression model, an analysis was performed on the same example data used above for the Kaplan-Meier survival analysis. As that method is similar to the regression analysis method, the covariates presented in Table 1 are used to estimate the hazard ratio of each covariate and, the corresponding P values are calculated.
Table 3 shows the hazard ratio and P value of each covariate estimated by the analysis using the Cox proportional hazards regression model. These analysis results were obtained by inputting all four covariates into the model, significant hazard ratio was obtained only for the type of antiemetic. The Cox proportional hazards regression model was estimated using the forward conditional method based on the likelihood ratio, and the antiemetics and opioid analgesics used intraoperatively were included in the equation. The hazard ratio for the antiemetics was estimated at 2.0 (95% CI: 1.2–3.3, P = 0.009); antiemetic agent B showed a twofold higher risk of nausea/vomiting during the first 24 postoperative hours compared with antiemetic agent A, and the intraoperative use of fentanyl showed a 4.7-fold risk of postoperative nausea/vomiting compared with remifentanil (hazard ratio 4.7, 95% CI: 2.8–8.1, P < 0.001). The cumulative survival for Group B was found to decrease rapidly (increase in postoperative occurrence of nausea/vomiting) over time when compared with that of Group A (Fig. 5).
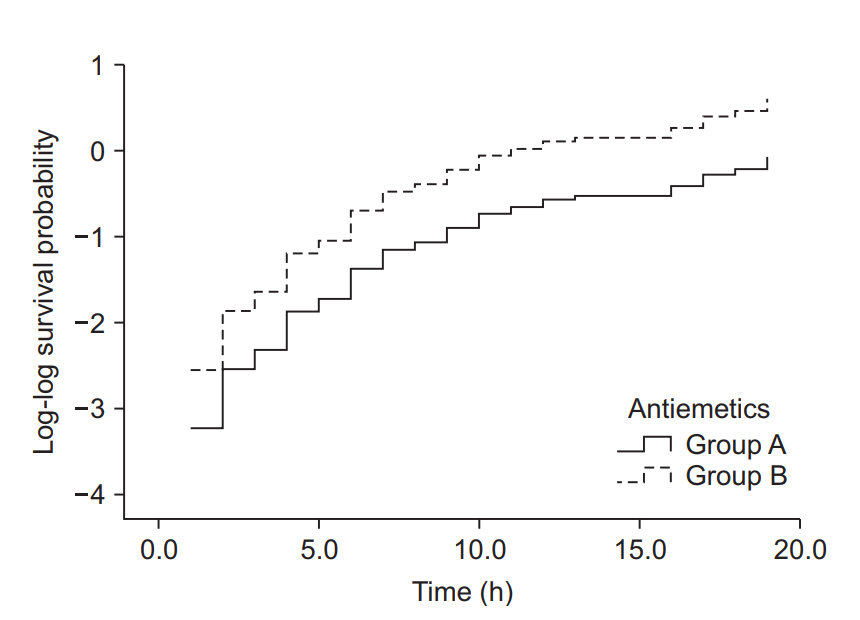
As briefly mentioned above, any estimation based on the Cox proportional hazards regression model must be followed by testing whether the proportional hazards assumption is satisfied. For the example data used here, the log minus log plot (LML plot) is presented as the simplest method for diagnosing problems with the model. The LML plot is a graph constructed by applying the log-log transformation to the survival function. Some statistical program packages optionally output this graph after an analysis based on the Cox proportional hazards regression model, making it possible to easily check compliance with the basic assumption that the hazard ratio is constant throughout the study period. This method for checking compliance with the proportional hazards assumption is essential when using the two survival analysis methods presented in this study, in that a quick intuitive verification is possible by examining the graph, in which the logarithm of the time and the logarithm of the negative logarithm of the estimated survival function are plotted on the x and y axes, respectively. If the LML plots for the comparison groups run parallel to each other without intersecting or meeting, the proportional hazards assumption can be considered valid [21].
Fig. 6 shows the LML plot for the example data. The two curves representing the two antiemetic groups run parallel without meeting or intersecting, demonstrating that the hazard ratios of the two groups with respect to the postoperative nausea/vomiting symptom manifestation are constant over time. In case of a violation of this assumption, which is indicative of the inaccuracy of the Cox proportional hazards regression model, it is desirable to use other methods allowing analysis of time-dependent influences, such as time-dependent Cox regression analysis (non-proportional hazards model).
Sample Size for Survival Analysis
Survival analysis is an analysis method that analyzes the time to an event of interest. In the log-rank test or Cox proportional hazards regression model, the hazard ratio is used for sample size calculation [22]. Just as a normal distribution and an effect size, e.g., Cohen’s h, are presupposed in other statistical methods for checking the statistical power or calculating the required sample size, the underlying survival model and effect size must be defined prior to calculating the sample size for survival analysis. In the log-rank test or Kaplan-Meier survival analysis, the survival function is estimated on the basis of the proportional hazards assumption, and the survival function and hazard ratio are correlated under the assumption of an exponential model.9) In survival analysis based on the proportional hazards assumption, the hazard ratio (presumed to have a constant value throughout the observation period) is used as the effect size [23].
In a study design including survival analysis, the sample size calculation begins with determination of the expected value of the incidence rate of a specific event in the hypothesis formulation stage10) and setting the hazard ratios of the two groups to be compared. For example, if the incidence rate for the experimental group is 20% lower than that of the control group, the hazard ratio is 0.8 (alternative hypothesis). The proportional hazards assumption presupposes the maintenance of the hazard ratio at a constant value throughout the observation period, and the null hypothesis is that “there is no difference in the risk of the two groups for experiencing the event,” i.e., hazard ratio = 1 [24].
Once the alternative hypothesis and the null hypothesis for the hazard ratio are formulated, they can be used for estimating the event count required to generate the desired significance level (α) and statistical power (β) (Equation 3).
Given that not all subjects experience the event during the study period, the sample size must be calculated using the total event count and the probability of experiencing an event (Equation 4).
The probability of experiencing an events (denominator) can be expressed as “1 – probability of survival.” The probability value can be estimated by the ratios between the number of patients of each group and the survival functions (Equation 5).
The probability of survival can be estimated using the survival function, as explained above. However, the statistical purpose of using survival analysis is to estimate the survival function, and therefore the survival function cannot be used for estimating the probability of events in the study design stage. Consequently, the probability of events is estimated using a pre-existing estimate of the incidence rate. Incidence rates taken from the literature often do not consider the time factor, and the details of the studies from which they are taken should be examined well.11) If the literature does not provide an incidence rate including the time factor, a pilot test should be designed for incidence rate estimation. An incidence rate estimate including the time factor is the event count per uniform time segment, such as the person-day or person-year, and represents the hazard ratio in the time segment concerned. Using the hazard ratio, it is possible to estimate the survival function based on the proportional hazards assumption, as well as the survival functions of the groups to be compared, using the hazard ratio set in the hypothesis formulation stage.
Using the example case of the recurrence of back pain, let us assume that a new drug B decreases the recurrence of back pain by 30% relative to conventional drug A, and calculate the hypothesis-testing sample size required to yield 80% statistical power at the 5% significance level. Suppose that a pilot test was performed to allow sample size calculation. Two of the five patients that received conventional drug A developed recurrence of back pain after epidural injection. Supposing that these five patients were observed for four weeks on average, the hazard rate (λ) is 2/(5 × 4 weeks) = 0.1/person-week. The value of the 4-week survival function for conventional drug A, estimated using the relationship between the survival function and hazard function, is SA (4) = exp (−0.1 × 4) = 0.018. Since new drug B decreases recurrence by 30%, the hazard ratio is 0.7, and the value of the 4-week survival function for new drug B is SB (4) = exp ((−0.1 × 0.7) × 4) = 0.061. If both groups have the same sample size, π1 = π2 = 0.5, the probability of an event, which is the denominator of the sample size calculation formula, is 1 − (π1S1 (t) + π2S2 (t)) = 1 − (0.5 × 0.018 + 0.5 × 0.061) = 0.960. The total event count, which is the numerator of the sample size calculation formula, can be obtained from Equation 3. zα/2 and zβ, which represent the values of probability in a standard normal distribution, are 1.96 and 0.842, respectively, for a significance level of 0.05 and statistical power of 80%. With the values of π1 and π2 set to 0.5 each and the hazard ratio set at 0.7, the total event count required is (1.96 + 0.842)2/{0.5 × 0.5 × (log0.7)2} = 246.9, i.e., 247 events. Substituting this value and the incidence rate into Equation 4, 247/0.960 = 257.3, i.e., 258 is obtained. Applying the generally assumed withdrawal rate of 10% to the value obtained, 258/(1 − 0.1) = 286.7, i.e., a total of 287 subjects, is set as the required sample size. With the group size ratio set at 0.5, 144 subjects are to be assigned to each group.12)
Conclusions
Survival analysis is a statistical method that allows comparison of final outcomes along with differences occurring within the observation period, by making use of the time factor. Studies in the field of anesthesia and pain medicine often analyze shortterm or long-term time-dependent outcomes, and survival analysis contributes to enhancing the efficiency of data comparison and presenting stronger bases for supporting the hypotheses formulated. The main focus of this article has been on interpreting studies using survival analysis. In future studies, however, it should be possible to present more diverse and interesting results in testing hypotheses, designing studies, and conducting them by applying survival analysis more intensely.