Introduction
The central limit theorem is the most fundamental theory in modern statistics. Without this theorem, parametric tests based on the assumption that sample data come from a population with fixed parameters determining its probability distribution would not exist. With the central limit theorem, parametric tests have higher statistical power than non-parametric tests, which do not require probability distribution assumptions. Currently, multiple parametric tests are used to assess the statistical validity of clinical studies performed by medical researchers; however, most researchers are unaware of the value of the central limit theorem, despite their routine use of parametric tests. Thus, clinical researchers would benefit from knowing what the central limit theorem is and how it has become the basis for parametric tests. This review aims to address these topics. The proof of the central limit theorem is described in the appendix, with the necessary mathematical concepts (e.g., moment-generating function and Taylor's formula) required for understanding the proof. However, some mathematical techniques (e.g., differential and integral calculus) were omitted due to space limitations.
Basic Concepts of Central Limit Theorem
In statistics, a population is the set of all items, people, or events of interest. In reality, however, collecting all such elements of the population requires considerable effort and is often not possible. For example, it is not possible to investigate the proficiency of every anesthesiologist, worldwide, in performing awake nasotracheal intubations. To make inferences regarding the population, however, a subset of the population (sample) can be used. A sample of sufficient size that is randomly selected can be used to estimate the parameters of the population using inferential statistics. A finite number of samples are attainable from the population depending on the size of the sample and the population itself. For example, all samples with a size of 1 obtained at random, with replacement, from the population {3,6,9,30} would be {3},{6},{9}, and {30}. If the sample size is 2, a total of 4 × 4 = 42 = 16 samples, which are {3,3},{3,6},{3,9},{3,30},{6,3},{6,6}...{9,30},{30,3},{30,6},{30,9}, and {30,30}, would be possible. In this way, 4n samples with a size of n would be obtained from the population. Here, we consider the distribution of the sample means.
The population mean, µ, and variance, σ2, are:
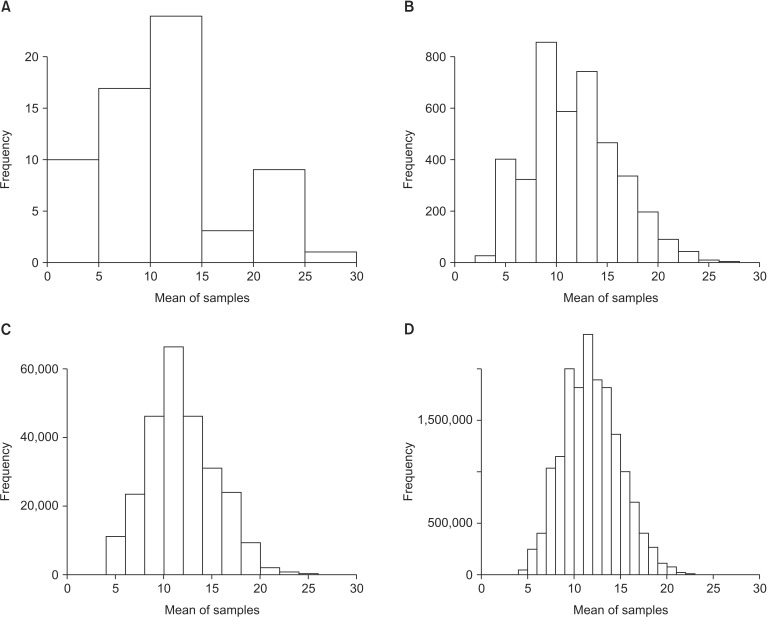
A simple rando m sampling with replacement from the population produces 4 × 4 × 4 = 43 = 64 samples with a size of 3 (Table 1). The mean and variance of the 64 sample means are 12 (the population mean) and 37.5 = σ 2 n = 112.5 3 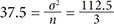 , respectively; however, the distribution of the means of samples is skewed (Fig. 1A).
, respectively; however, the distribution of the means of samples is skewed (Fig. 1A).
, respectively; however, the distribution of the means of samples is skewed (Fig. 1A).When a simple random sampling with replacement is performed for samples with a size of 6, 4 × 4 × 4 × 4 × 4 × 4 = 46 = 4,096 samples are possible (Table 2). The mean and variance of the 4,096 sample means are 12 (the population mean) and 18.75 = σ 2 n = 112.5 6  , respectively. Compared to the distribution of the means of samples with a size of 3, that of the means of samples with a size of 6 is less skewed. Importantly, the sample means also gather around the population mean. (Fig. 1B). Thus, the larger the sample size (n), the more closely the sample means gather symmetrically around the population mean (µ) and have a corresponding reduction in the variance (
, respectively. Compared to the distribution of the means of samples with a size of 3, that of the means of samples with a size of 6 is less skewed. Importantly, the sample means also gather around the population mean. (Fig. 1B). Thus, the larger the sample size (n), the more closely the sample means gather symmetrically around the population mean (µ) and have a corresponding reduction in the variance (σ 2 n 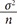 ) (Figs. 1C and 1D). If Figs. 1A to 1D are converted to the probability density function by replacing the variable “frequency” with another variable “probability” on the vertical axis, their shapes remain unchanged.
) (Figs. 1C and 1D). If Figs. 1A to 1D are converted to the probability density function by replacing the variable “frequency” with another variable “probability” on the vertical axis, their shapes remain unchanged.
, respectively. Compared to the distribution of the means of samples with a size of 3, that of the means of samples with a size of 6 is less skewed. Importantly, the sample means also gather around the population mean. (Fig. 1B). Thus, the larger the sample size (n), the more closely the sample means gather symmetrically around the population mean (µ) and have a corresponding reduction in the variance () (Figs. 1C and 1D). If Figs. 1A to 1D are converted to the probability density function by replacing the variable “frequency” with another variable “probability” on the vertical axis, their shapes remain unchanged.In general, as the sample size from the population increases, its mean gathers more closely around the population mean with a decrease in variance. Thus, as the sample size approaches infinity, the sample means approximate the normal distribution with a mean, µ, and a variance, σ 2 n σ 2 n
. As shown above, the skewed distribution of the population does not affect the distribution of the sample means as the sample size increases. Therefore, the central limit theorem indicates that if the sample size is sufficiently large, the means of samples obtained using a random sampling with replacement are distributed normally with the mean, µ, and the variance, , regardless of the population distribution. Refer to the appendix for a near-complete proof of the central limit theorem, as well as the basic mathematical concepts required for its proof.Central Limit Theorem in the Real World
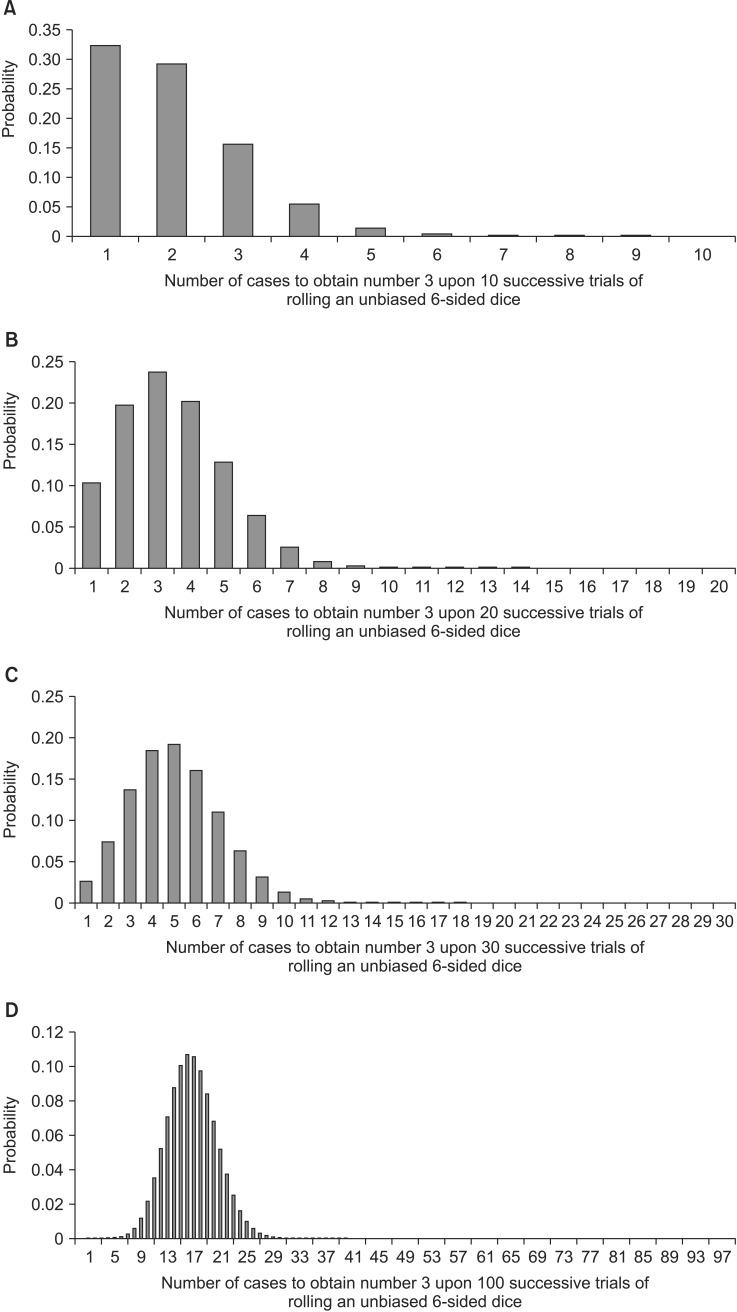
An unbiased, symmetric, 6-sided dice is rolled at random n times. The probability of rolling the number 3 x times in n successive independent trials has the following probability density distribution, which is called the binomial distribution:
n: number of in dependent trials (rolling a dice), x: number of times the number 3 is rolled in each trial, 1 6  : the probability of rolling the number 3 in each trial, 1 −
: the probability of rolling the number 3 in each trial, 1 − 1 6
: the probability of rolling the number 3 in each trial, 1 − : the probability of rolling a number other than 3 in each trial.The mathematical expectation of the random variable, X, (i.e., the number of times that the number 3 is rolled in each trial), which is also referred to as the mean of the distribution, is:
When n = 10, the probability has a skewed distribution (Fig. 2A); however, as n increases, the distribution becomes symmetric with respect to its mean (Figs. 2B–2D). As n approaches infinity, the binomial distribution approximates the normal distribution with a mean, np, and a variance, np(1 − p), where p is the probability constant for the occurrence of the specific event during each trial.
Central Limit Theorem in the Student's t-test
Since the central limit theorem determines the sampling distribution of the means with a sufficient size, a specific mean (X̅) can be standardized z = X - - µ σ n  and subsequently identified against the normal distribution with mean of 0 and variance of 12. In reality, however, the lack of a known population variance (σ2) prevents a determination of the probability density distribution.
and subsequently identified against the normal distribution with mean of 0 and variance of 12. In reality, however, the lack of a known population variance (σ2) prevents a determination of the probability density distribution.
and subsequently identified against the normal distribution with mean of 0 and variance of 12. In reality, however, the lack of a known population variance (σ2) prevents a determination of the probability density distribution.
Xi (i = 1, 2, ..., n): a sample from the population, N: the size of the population, µ: the mean of the population.
Notably, the Student's t-distribution was developed to use a sample variance (S) instead of a population variance (σ2).
xi (i = 1, 2, ..., n): a random sample from the population, n: sample size, X̅: the mean of the samples.
The specific mean (X̅) is studentized t = ( X - - µ ) S n 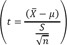 and its location is evaluated on the Student's t-distribution, based on the degree of freedom (n − 1). The shape of the Student's t-distribution is dependent on the degree of freedom. A low degree of freedom renders the peak of the Student's t-distribution lower than that of a normal distribution, although at some points, the tails have higher values than those of the normal distribution. As the degree of freedom increases, the Student's t-distribution approaches the normal distribution. At a degree of freedom of 30, the Student's t-distribution is regarded as equaling the normal distribution [1]. The underlying assumption for the Student's t-test is that samples should be obtained from a normally distributed population. However, since the distribution of population is not known, it should be determined whether the sample is normally distributed. This is particularly true for small sample sizes. If small sample sizes are normally distributed, the studentized distribution of the sample means is equal to the Student's t-distribution with a degree of freedom corresponding to the sample size. If the small samples are not normally distributed, non-parametric tests should be performed instead of the Student's t-test since they do not require assumptions about the distribution of population. If the sample size is 30, the studentized sampling distribution approximates the standard normal distribution and assumptions about the population distribution are meaningless since the sampling distribution is considered normal, according to the central limit theorem. Therefore, even if the mean of a sample of size > 30 is studentized using the variance, a normal distribution can be used for the probability distribution.
and its location is evaluated on the Student's t-distribution, based on the degree of freedom (n − 1). The shape of the Student's t-distribution is dependent on the degree of freedom. A low degree of freedom renders the peak of the Student's t-distribution lower than that of a normal distribution, although at some points, the tails have higher values than those of the normal distribution. As the degree of freedom increases, the Student's t-distribution approaches the normal distribution. At a degree of freedom of 30, the Student's t-distribution is regarded as equaling the normal distribution [1]. The underlying assumption for the Student's t-test is that samples should be obtained from a normally distributed population. However, since the distribution of population is not known, it should be determined whether the sample is normally distributed. This is particularly true for small sample sizes. If small sample sizes are normally distributed, the studentized distribution of the sample means is equal to the Student's t-distribution with a degree of freedom corresponding to the sample size. If the small samples are not normally distributed, non-parametric tests should be performed instead of the Student's t-test since they do not require assumptions about the distribution of population. If the sample size is 30, the studentized sampling distribution approximates the standard normal distribution and assumptions about the population distribution are meaningless since the sampling distribution is considered normal, according to the central limit theorem. Therefore, even if the mean of a sample of size > 30 is studentized using the variance, a normal distribution can be used for the probability distribution.
and its location is evaluated on the Student's t-distribution, based on the degree of freedom (n − 1). The shape of the Student's t-distribution is dependent on the degree of freedom. A low degree of freedom renders the peak of the Student's t-distribution lower than that of a normal distribution, although at some points, the tails have higher values than those of the normal distribution. As the degree of freedom increases, the Student's t-distribution approaches the normal distribution. At a degree of freedom of 30, the Student's t-distribution is regarded as equaling the normal distribution [1]. The underlying assumption for the Student's t-test is that samples should be obtained from a normally distributed population. However, since the distribution of population is not known, it should be determined whether the sample is normally distributed. This is particularly true for small sample sizes. If small sample sizes are normally distributed, the studentized distribution of the sample means is equal to the Student's t-distribution with a degree of freedom corresponding to the sample size. If the small samples are not normally distributed, non-parametric tests should be performed instead of the Student's t-test since they do not require assumptions about the distribution of population. If the sample size is 30, the studentized sampling distribution approximates the standard normal distribution and assumptions about the population distribution are meaningless since the sampling distribution is considered normal, according to the central limit theorem. Therefore, even if the mean of a sample of size > 30 is studentized using the variance, a normal distribution can be used for the probability distribution.